Creating a workflow
You can start either with a pre-built template or create your own data structure from scratch. You can also create a new workflow via the API. When you create an empty workflow, you’ll be greeted with an empty configuration. You need to describe the shape of the data that should be extracted from your documents.
Data types
A workflow configuration must have one or more objects to be extracted.Object
Object are the “root” nodes of a configuration. Each object can have multiple fields and/or tables. You must have at least one object defined in your configuration. You should treat objects like semantical groups for your data.Field
A field is a singular data variable that will be populated during extraction. There are 3-built in types:- Text
- Number
- Date
Table
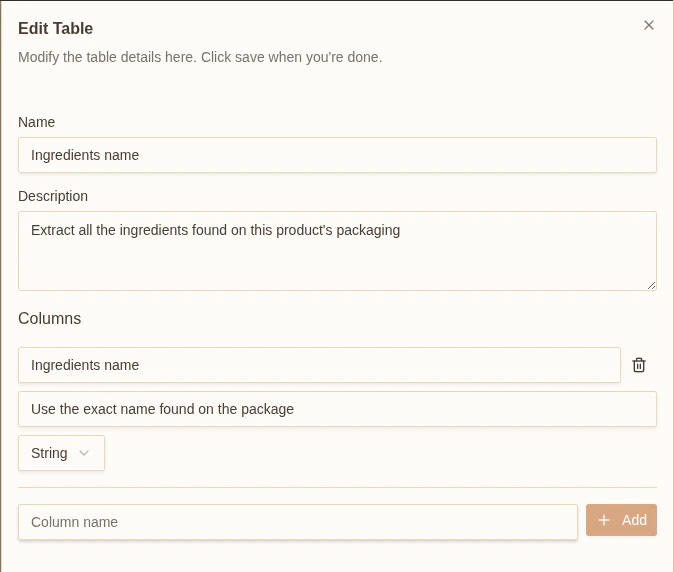
Tables are used to extract repetitive data such as lists or tables. Each table must have one or more columns, where each column definition is a Field Here’s an example of a list that extracts ingredients from a product photograph: